GPU
An overview of the NVIDIA H200 GPU
Inside the NVIDIA H200: Specifications, use cases, performance benchmarks, and a comparison of H200 vs H100 GPUs.
Learn more about the NVIDIA L40S, a versatile GPU that is designed to power a wide variety of applications, and check out NVIDIA L40S vs NVIDIA H100 vs NVIDIA A100 GPU comparisons.

Powered by the flexible Ada Lovelace architecture that includes both 4th Gen Tensor Cores and 3rd Gen ray tracing (RT) cores, the L40S is one of the most versatile GPUs in the NVIDIA lineup. While the Tensor cores and Deep Learning Super Sampling (DLSS) help deliver strong AI and data science performance, the RT cores enable photorealistic rendering, enhanced ray tracing, and powerful shading makes this data center GPU also suitable for professional visualization workloads.
Here’s a snapshot of the NVIDIA L40S specifications:
| NVIDIA L40S GPU Specs | |
|
GPU Architecture
|
NVIDIA Ada Lovelace
|
|
GPU Memory
|
48GB GDDR6 with ECC
|
|
Memory Bandwidth
|
864GB/s
|
|
Interconnect Interface
|
PCIe Gen4 x16: 64GB/s bidirectional
|
|
NVIDIA Ada Lovelace CUDA® Cores
|
18,176
|
|
NVIDIA Third-Generation RT Cores
|
142
|
|
NVIDIA 4th Gen Tensor Cores
|
568
|
|
NVIDIA® NVLink® Support
|
No
|
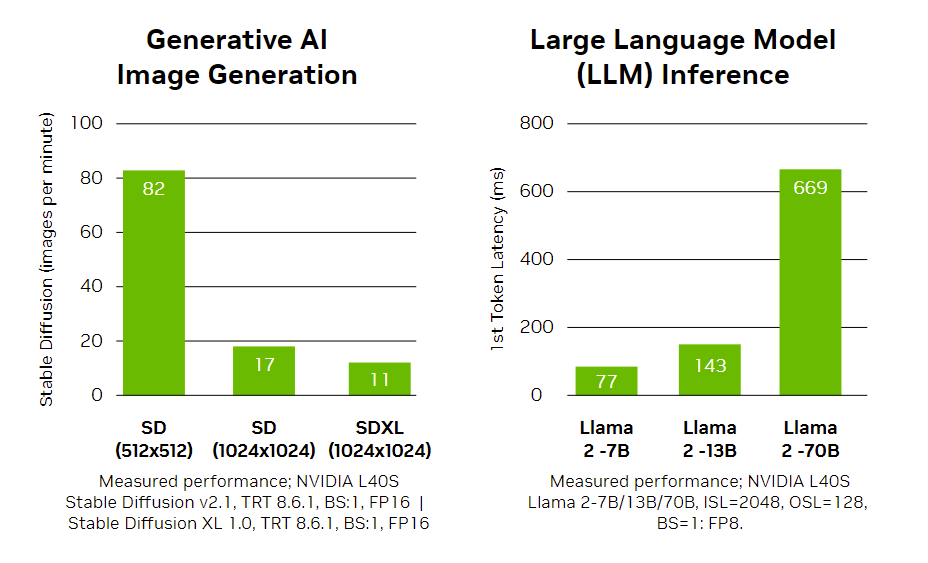
Consider NVIDIA L40S for these use cases
.png?width=800&height=160&name=Discord%20Banner%20(2).png)
| L40S | H100 SXM | H100 PCIe | |
|
GPU architecture
|
Ada Lovelace
|
Hopper
|
|
|
Use cases
|
AI inference, 3D graphics, rendering, video processing, engineering, architecture, VR
|
Foundation model training, AI inference, HPC, LLMs, Multimodal models, Image & video generation, Large scale production ready models
|
|
|
Fractional GPU support
|
No
|
Yes
|
|
|
Multi-GPU support
|
No
|
Yes
|
|
|
GPU memory (VRAM)
|
48 GB GDDR6 with ECC
|
80 GB HBM3
|
80 GB HBM2e
|
|
Memory Bandwidth
|
864 GB/s
|
3.35 TB/s
|
2 TB/s
|
|
NVLink support
|
No
|
Yes
|
Yes
|
|
FP64
|
Not supported
|
33.5 TFLOPS
|
25.6 TFLOPS
|
|
FP64 Tensor Core
|
Not supported
|
66.9 TFLOPS
|
51.2 TFLOPS
|
|
FP32
|
91.6 TFLOPS
|
66.9 TFLOPS
|
51.2 TFLOPS
|
|
FP16
|
Not available
|
133.8 TFLOPS
|
102.4 TFLOPS
|
|
BF16
|
Not available
|
133.8 TFLOPS
|
102.4 TFLOPS
|
|
TF32 Tensor Core
|
183 TFLOPS I 366 TFLOPS*
|
494.7 TFLOPS | 989.4 TFLOPS*
|
378 TFLOPS | 756 TFLOPS*
|
|
FP16 Tensor Core
|
362.05 TFLOPS I 733 TFLOPS*
|
989.4 TFLOPS | 1978.9 TFLOPS*
|
756 TFLOPS | 1513 TFLOPS*
|
|
BF16 Tensor Core
|
362.05 TFLOPS I 733 TFLOPS*
|
989.4 TFLOPS | 1978.9 TFLOPS*
|
756 TFLOPS | 1513 TFLOPS*
|
|
FP8 Tensor Core
|
733 TFLOPS I 1,466 TFLOPS*
|
1978.9 TFLOPS | 3957.8 TFLOPS*
|
1513 TFLOPS | 3026 TFLOPS*
|
|
INT8 Tensor Core
|
733 TOPS I 1,466TOPS*
|
1978.9 TOPS | 3957.8 TOPS*
|
1513 TOPS | 3026 TOPS*
|
|
Llama-2-7B **
|
L40S Throughput
|
H100 SXM High Throughput
|
L40S Cost / 1M tokens
|
H100 SXM Cost / 1M tokens
|
|
Input tokens = 128, Output tokens = 128
|
6,656 tokens/s/GPU
|
17,685 tokens/s/GPU
|
$0.082
|
$0.059
|
|
Input tokens = 128, Output tokens = 2048
|
1,592 tokens/s/GPU
|
6,815 tokens/s/GPU
|
$0.342
|
$0.155
|
|
Input tokens = 2048, Output tokens = 2048
|
653 tokens/s/GPU
|
2,820 tokens/s/GPU
|
$0.834 |
$0.374 |
|
Stable Diffusion XL
|
NVIDIA L40S
|
NVIDIA H100 SXM
|
|
Images per hour*
|
1296
|
2952
|
|
Ori Global Cloud Pricing
|
$1.96/hr
|
$3.8/hr
|
|
Latency per image
|
2812.19 ms
|
1213.17 ms
|
|
Cost of 1000 images**
|
$1.512
|
$1.287
|

|
L40S
|
A100 PCIe
|
|
|
GPU architecture
|
Ada Lovelace
|
Ampere
|
|
Use cases
|
AI inference, 3D graphics, rendering, video processing
|
AI Training, AI inference, HPC / Scientific computing
|
|
Fractional GPU support
|
No
|
Yes
|
|
Multi-GPU support
|
No
|
Yes
|
|
GPU memory (VRAM)
|
48GB GDDR6 memory with ECC
|
80 GB HBM2e
|
|
Memory Bandwidth
|
864GB/s
|
1,935GB/s
|
|
NVLink support
|
No
|
Yes
|
|
FP64, FP64 Tensor Core support
|
No
|
Yes
|
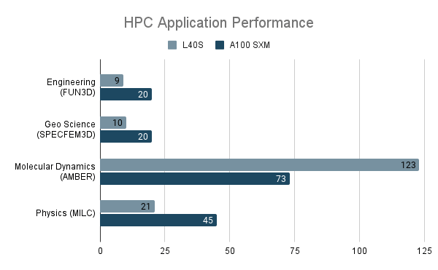
The NVIDIA A100, with its support for 64-bit formats, strong fp64 performance and larger memory capacity outperforms the L40S for HPC workloads.
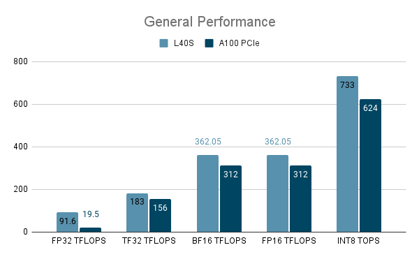
The NVIDIA L40S GPU offers a versatile balance of AI inference performance and 3D rendering capabilities, making it ideal for small to medium AI models, graphics-heavy applications, and multimodal models. It is a cost-effective alternative to the H100 and A100 GPUs for smaller inference tasks, while being well-suited for AI and content creation workloads.
Deploy NVIDIA L40S on Ori Global Cloud in any of these modes:

Inside the NVIDIA H200: Specifications, use cases, performance benchmarks, and a comparison of H200 vs H100 GPUs.
General availability of Virtual Machines with NVIDIA GPUs (H100, A100, V100) in Ori Global Cloud.
Accelerate your AI with NVIDIA H200 GPUs on Ori to train models and run inference more efficiently than ever before.
Build a modern GPU cloud with Ori to accelerate your AI workloads at scale.
