AI
General availability of Virtual Machines with NVIDIA GPUs
General availability of Virtual Machines with NVIDIA GPUs (H100, A100, V100) in Ori Global Cloud.
When should you opt for H100 GPUs over A100s for ML training and inference? Here's a top down view when considering cost, performance and use case.

As building Generative AI becomes more mainstream, there are two NVIDIA GPU models that have risen to the top of every AI builder’s infrastructure wishlist—the H100 and A100. The H100 was released in 2022 and is the most capable card in the market right now. The A100 may be older, but is still familiar, reliable and powerful enough to handle demanding AI workloads.
There’s a lot of information out there on the individual GPU specs, but we repeatedly hear from customers that they still aren’t sure which GPUs are best for their workload and budget. H100s look more expensive on the surface, but can they save more money by performing tasks faster? A100s and H100s have the same memory size, so where do they differ the most?
With this post, we want to help you understand the key differences to look out for between the main GPUs (H100 vs A100) currently being used for ML training and inference.
TABLE 1 - Technical Specifications NVIDIA A100 vs H100
According to NVIDIA, the H100 performance can be up to 30x better for inference and 9x better for training. This comes from higher GPU memory bandwidth, an upgraded NVLink with bandwidth of up to 900 GB/s and the higher compute performance with the Floating-Points Operations per Second (FLOPS) of the H100 over 3x higher than those of the A100.
Tensor Cores: New fourth-generation Tensor Cores on the H100 are up to 6x faster chip-to-chip compared to A100, including per-streaming multiprocessor (SM) speedup (2x Matrix Multiply-Accumulate), additional SM count, and higher clocks of H100. Worth highlighting, the H100 Tensor Cores supports the 8-bit floating FP8 inputs which substantially increase speed at that precision.
Memory: The H100 SXM has a HBM3 memory that provides nearly a 2x bandwidth increase over the A100. The H100 SXM5 GPU is the world’s first GPU with HBM3 memory delivering 3+ TB/sec of memory bandwidth. Both the A100 and the H100 have up to 80GB of GPU memory.
NVLink: The fourth-generation NVIDIA NVLink in the H100 SXM provides a 50% bandwidth increase over the prior generation NVLink with 900 GB/sec total bandwidth for multi-GPU IO operating at 7x the bandwidth of PCIe Gen 5.
At launch of the H100, NVIDIA claimed that the H100 could “deliver up to 9x faster AI training and up to 30x faster AI inference speedups on large language models compared to the prior generation A100.” Based on their own published figures and tests this is the case. However, the selection of the models tested and the parameters (i.e. size and batches) for the tests were more favorable to the H100, reason for which we need to take these figures with a pinch of salt.
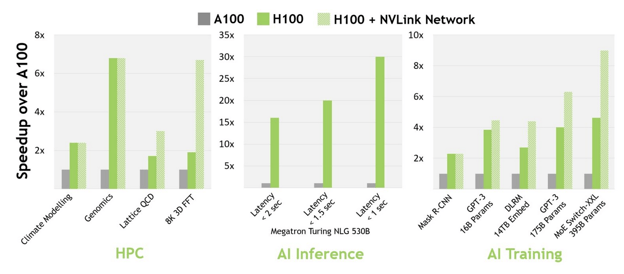
NVIDIA Benchmarking - NVIDIA H100 vs A100
Other sources have done their own benchmarking showing that the speed up of the H100 over the A100 for training is more around the 3x mark. For example, MosaicML ran a series of tests with varying parameter count on language models and found the following:
MosaicML Benchmarking - NVIDIA H100 vs A100
Lower improvements were obtained by LambaLabs when they tried to benchmark both GPUs when training a Large Language Model (GPT3-like model with 175B parameters) using FlashAttention2. In this case, the H100 performed ~2.1x better than the A100.
.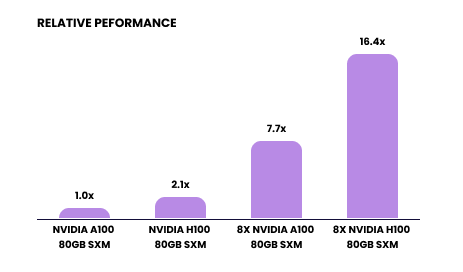
FlashAttention2 Training on a 175B LLM
Although these benchmarks provide valuable performance data, it's not the only consideration. It's crucial to match the GPU to the specific AI task at hand. Additionally, the overall cost must be factored into the decision to ensure the chosen GPU offers the best value and efficiency for its intended use.
The performance benchmarking shows that the H100 comes up ahead but does it make sense from a financial standpoint? After all, the H100 is regularly more expensive than the A100 in most cloud providers. For example at Ori, you can find A100s starting at $1.80 per hour while the H100 starts at $3.08 per hour (71% more expensive).
To get a better understanding if the H100 is worth the increased cost we can use work from MosaicML which estimated the time required to train a 7B parameter LLM on 134B tokens
FlashAttention2 Training on a 175B LLM
If we consider Ori’s pricing for these GPUs we can see that training such a model on a pod of H100s can be up to 39% cheaper and take up 64% less time to train. Of course this comparison is mainly relevant for training LLM training at FP8 precision and might not hold for other deep learning or HPC use cases.
Get started at ori.co and get access to on-demand H100s, A100s and more GPUs from Ori Global Cloud (OGC). Alternatively, contact us and we can help you set up a private GPU cluster that matches your every need.
General availability of Virtual Machines with NVIDIA GPUs (H100, A100, V100) in Ori Global Cloud.
Learn more about the NVIDIA L40S, a versatile GPU that is designed to power a wide variety of applications, and check out NVIDIA L40S vs NVIDIA H100...
Inside the NVIDIA H200: Specifications, use cases, performance benchmarks, and a comparison of H200 vs H100 GPUs.
Build a modern GPU cloud with Ori to accelerate your AI workloads at scale.
