Tutorial
How to deploy an interactive chatbot with Ori Inference Endpoints and Gradio
Learn how to deploy chatbots based on LLMs with Ori Inference Endpoints and Gradio
Learn how to deploy and scale Qwen 2.5 1.5B effortlessly with Ori Inference Endpoints.

Alibaba Cloud’s Qwen 2.5 foundation model family has become one of the most popular open source LLMs with model downloads topping 40 million and more than 50,000 derivative models. Qwen 2.5 offers coding, math and generalist text-generation variants in various model sizes, and with support for 29 languages, it provides plenty of choice for different use cases.
Here’s a summary of the Qwen 2.5 specs and performance benchmarks:
| Qwen 2.5 1.5B | |
|
Architecture
|
Transformers with RoPE, SwiGLU, RMSNorm, Attention QKV bias and tied word embeddings
|
|
Parameters
|
1.54B (Non-Embedding: 1.31B) |
|
Model Variants
|
2.5, 2.5 Coder, 2.5 Math
|
|
Context Length / Generation Length
|
Full 32,768 tokens and generation 8192 tokens
|
|
Licensing
|
Apache 2.0: Commercial and research
|
|
Datasets
|
Qwen 2.5 1.5B
|
Gemma2-2.6B
|
|
MMLU
|
60.9
|
52.2
|
|
MMLU-pro
|
28.5
|
23.0
|
|
MMLU-redux
|
58.5
|
50.9
|
|
BBH
|
45.1
|
41.9
|
|
ARC-C
|
54.7
|
55.7
|
|
TruthfulQA
|
46.6
|
36.2
|
|
Winogrande
|
65.0
|
71.5
|
|
Hellaswag
|
67.9
|
74.6
|
.png?width=800&height=160&name=Discord%20Banner%20(2).png)
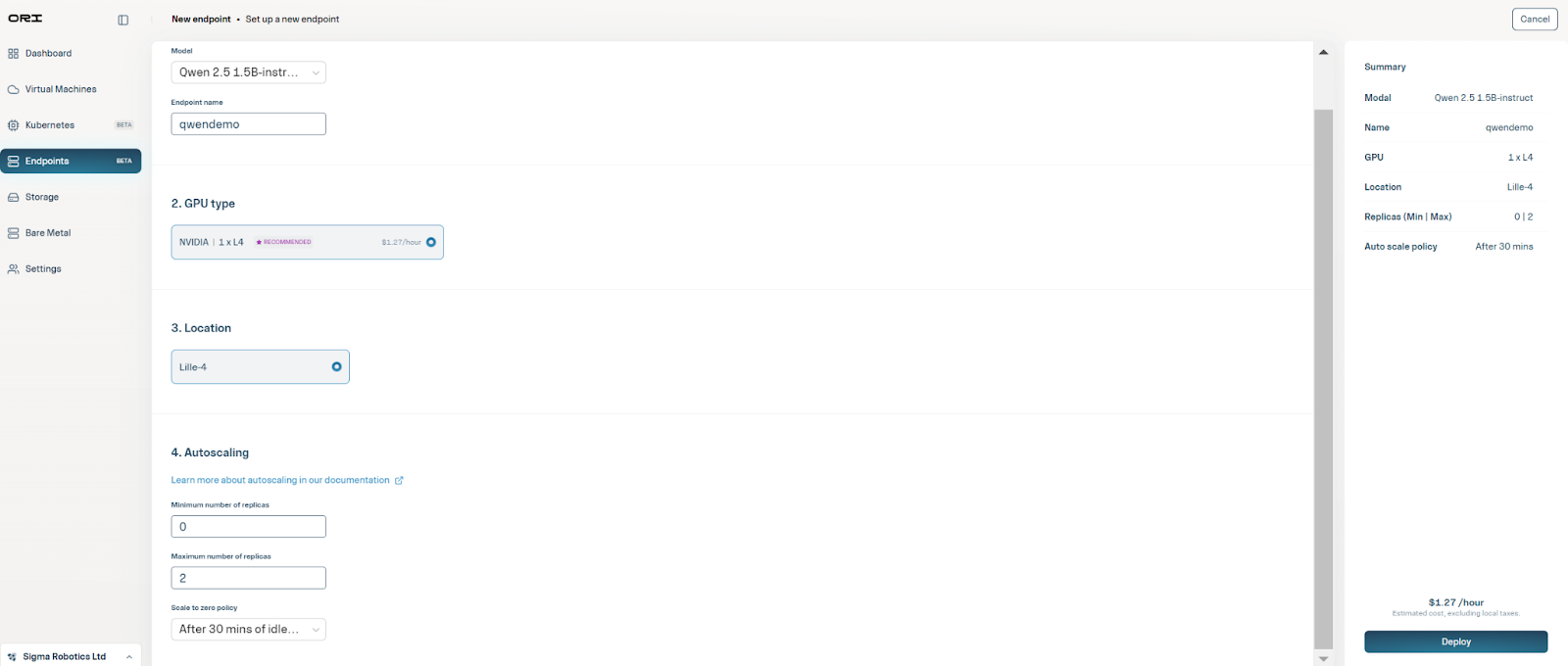
Step 2: Select Qwen 2.5 1.5B from the model drop down list.
Step 3: Choose Compute Resources
Step 4: Ori Inference Endpoints enables you to scale your inference up or down automatically. Configure autoscaling:
Step 5: Hit Deploy and your Inference Endpoint will be ready shortly!
Here’s a snapshot of the Endpoint creation flow:
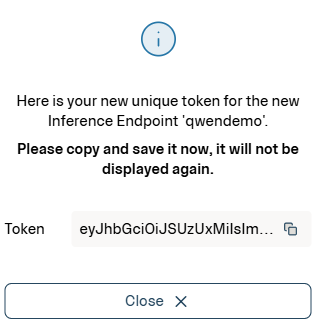
As soon as your endpoint is created, you are provided with an Authorization Token. Accessing inference endpoints requires your authorization token to ensure secure access through the Authorization Header.
You'll be able to see a sample cURL command under the endpoint details. Customize your prompt if needed and run the command from your terminal:


Learn how to deploy chatbots based on LLMs with Ori Inference Endpoints and Gradio
Say hello to Ori Inference Endpoints, an easy and scalable way to deploy state-of-the-art machine learning models as API endpoints.
Ori secures strategic investment from Wa’ed Ventures to fuel expansion in Saudi Arabia and the Middle East
Build a modern GPU cloud with Ori to accelerate your AI workloads at scale.
