Video generation is the next frontier for generative AI. Unlike generating images or text, generative video is harder because it needs more compute, has less accessible training datasets, and includes more variables such as smooth motion, temporal coherence and frame aesthetics.
Models like Llama, Pixtral, Flux, and many others have demonstrated how open-source AI drives faster and more widespread innovation across the field. That’s why Genmo’s announcement of the Mochi 1 model is a key step forward in advancing generative AI.
Here’s a snapshot of Mochi specs:
| |
Mochi 1 Specifications |
|
Model Architecture
|
Diffusion models built on Asymmetric Diffusion Transformer (AsymmDiT) architecture
|
|
Parameters
|
10B |
|
Context
|
Context window of 44,520 video tokens |
|
Resolution
|
480p |
|
Frames
|
Up to 30 frames per second and a length of 5.4 seconds |
|
Licensing
|
|
Genmo AI's benchmark results showcase state of the art (SOTA) performance in both prompt adherence and ELO scores. These metrics indicate how close the result is to the user’s prompt and fluidity in motion.
.png?width=1920&height=384&name=Discord%20Banner%20(2).png)
Deploy Genmo Mochi Video with ComfyUI on an Ori GPU instance
ComfyUI is an open-source AI tool developed and maintained by Comfy Org for running image and video generation models. Check out their Github here.
Pre-requisites:
Create a GPU virtual machine (VM) on Ori Global Cloud. We chose the NVIDIA H100 SXM with 80 GB VRAM for this demo, but the optimized ComfyUI version also runs on GPUs with lesser memory. A powerful GPU with more memory enhances the variational autoencoder (VAE), but ComfyUI will switch to tiled VAE automatically if memory is limited.
Install ComfyUI:
Step 1:
sudo apt update
sudo apt install git
Step 2: Download the ComfyUI files
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
Step 3: If you didn’t add the init script for Pytorch, when creating the virtual machine
pip install torch torchvision torchaudio
Step 4: Install dependencies
pip install -r requirements.txt
Step 5: Install ComfyUI Manager which helps you manage your custom nodes and instance.
cd custom_nodes
git clone https://github.com/ltdrdata/ComfyUI-Manager.git
Run Mochi 1 on ComfyUI
Step 1: Download Mochi weights from Hugging Face
cd ComfyUI/models/diffusion_models
wget https://huggingface.co/Comfy-Org/mochi_preview_repackaged/resolve/main/split_files/diffusion_models/mochi_preview_bf16.safetensors
wget https://huggingface.co/Comfy-Org/mochi_preview_repackaged/resolve/main/split_files/diffusion_models/mochi_preview_fp8_scaled.safetensors
Step 2: Download the FP 16 orFP8 text encoders, or both.
cd ComfyUI/models/clip
wget https://huggingface.co/Comfy-Org/mochi_preview_repackaged/resolve/main/split_files/text_encoders/t5xxl_fp16.safetensors
wget https://huggingface.co/Comfy-Org/mochi_preview_repackaged/resolve/main/split_files/text_encoders/t5xxl_fp8_e4m3fn_scaled.safetensors
Step 3: Download VAE
cd ComfyUI/models/vae
wget https://huggingface.co/Comfy-Org/mochi_preview_repackaged/resolve/main/split_files/vae/mochi_vae.safetensors
Step 4: Run ComfyUI
python3.10 main.py --listen=0.0.0.0 --port=8080
ComfyUI uses port 8188 by default, but we configured it to use a default open port on the SXM node for easier access.
Step 5: In your browser open http://”virtual machine address”:8080. Drag the wolf image in this
link to your ComfyUI tab which will automatically load the workflow for FP 16.
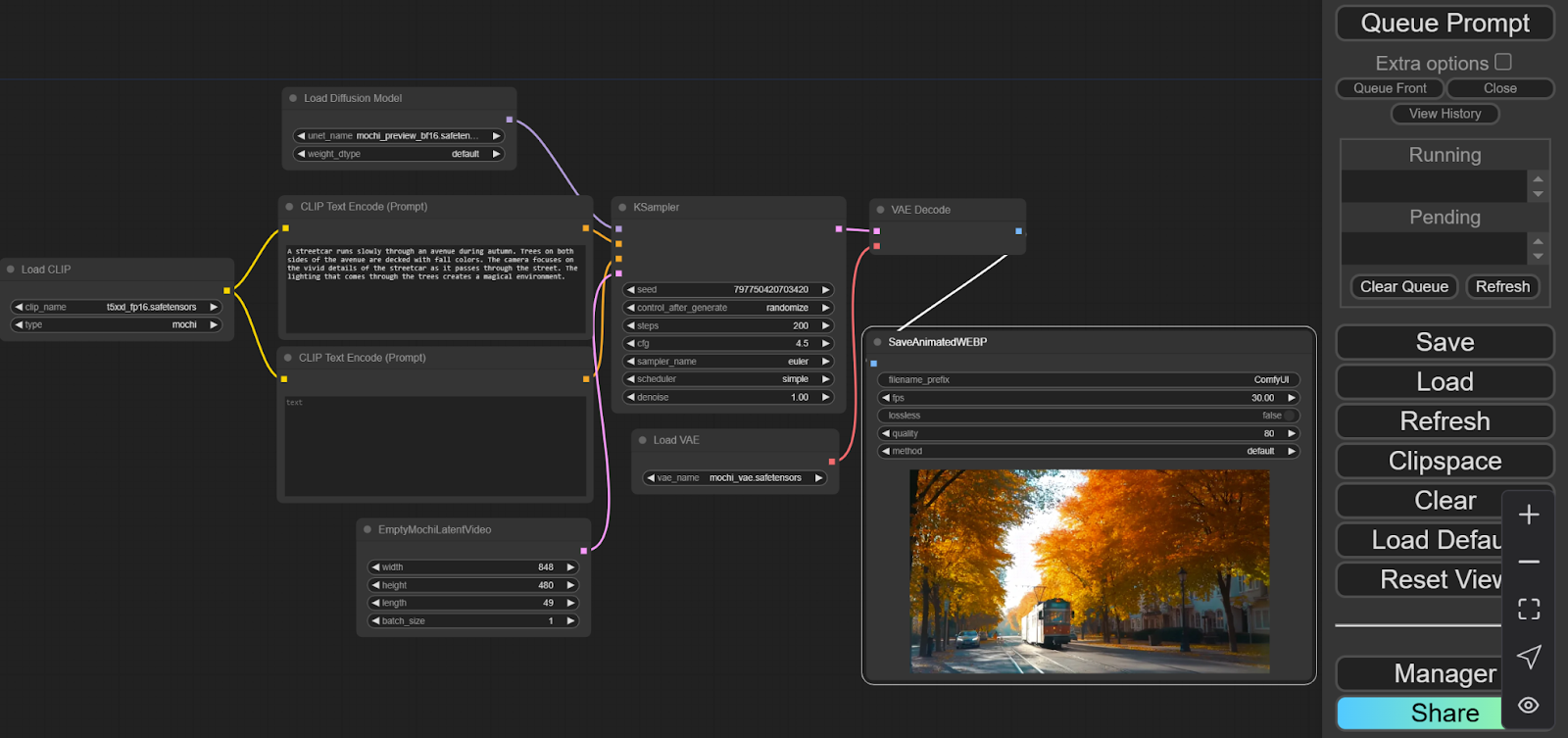
Your ComfyUI workflow will resemble the image below. Adjust length (frame count), frames per second, and model iterations, then click "Queue Prompt" to generate the video.
How good is Genmo Mochi 1?
Mochi 1 Preview demonstrated strong prompt adherence and impressive video dynamics. Reducing the iteration count and frame count can significantly shorten video generation time, which could otherwise take 45 minutes for a 5-second clip at 200 iterations and 30 fps. We recommend testing the model several times to find a frame rate and iteration count that balance your needs and efficiency.
We observed that using detailed prompts—including specifics on camera angles, motion type, lighting, and environment—yielded better results. With the right prompts, Mochi 1 showed remarkable flexibility in frame aesthetics. While the motion occasionally appeared glitchy, it was generally smooth and fluid. The Genmo Mochi AI model also excelled in executing close-up shots with impressive clarity.
The model struggles with text insertion, a challenge that has also affected image generation models in the past. However, recent improvements in image models show promise, and we expect Genmo to enhance this feature in future updates. Each model iteration takes about 14 seconds which means generating a 5 second clip with 200 iterations takes more than 45 minutes (14*200 seconds), whereas closed-source video generation models are typically much faster.
Though Genmo currently limits the model to 480p resolution and 5-second videos, we’re excited about their upcoming 720p version of the text-to-video model and the future of open source video generation.
Here are some example of video content generated by Mochi 1:
Prompt: A panda waiting for a train is reading a book in a picturesque setting of a train station during the tranquil Afternoon hours. Set against the backdrop of a serene summer landscape characterized by a Sunny atmosphere, enhance the scene with the inclusion of benches strategically placed to complement the surroundings. As the scene unfolds, use a gradual zoom in camera movement to gradually reveal the intricacies of the environment.
Prompt:
A streetcar runs slowly through an avenue during autumn. Trees on both sides of the avenue are decked with fall colors. The camera focuses on the vivid details of the streetcar as it passes through the street. The lighting that comes through the trees creates a magical environment.
Prompt:
A movie trailer featuring a 30 year old woman on Mars who is walking in a cool spacesuit, cinematic style, shot on 35mm film. A large, circular building with glass windows is clearly visible in the backdrop. The scene is brightly lit with tones of red. The environment evokes awe and creates excitement.
Prompt: A large, majestic dragon with olive green scales and flaming red eyes is set against the backdrop of a serene, snowy valley. The video begins with a tracking shot of the valley and then the camera zooms in on the dragon highlighting the details on its face. To maintain visual clarity of this video, every element within the frame is crisp and discernible.
Prompt: A close up of cold pressed fruit juice being poured into a glass bottle.
Prompt: Floor tiles lit up in neon blue in the style of PCB wiring
Prompt: Top view of a vibrant rainforest with a macaw sitting on a tree. As the scene progresses, the camera zooms in on the macaw.
Prompt: A title screen with a rugged and grainy grey backdrop. The lighting creates an environment of wonder and excitement. The word “ORI” appears on the screen in slow motion and the camera moves closer to the text.
As you can see in the video above, Mochi1 failed to generate the text “ORI”
Genmo AI has also launched a playground that allows users to create a limited number of videos per day. Check out community creations to see what users have created with this new AI text-to-video generator.
Mochi 1 is an excellent tool for generating short video clips with impressive motion quality. While it has some limitations, including lower resolution, challenges in text handling, and longer generation times, it marks a significant milestone in open source AI. As generative video continues to grow in popularity, we look forward to exploring Mochi 1 HD soon.
Alternative ways to run Mochi 1 Preview
If you want to run the full version as released by Genmo, with Gradio or directly from the CLI, check out these steps:
Genmo Mochi Requirements
Genmo recommends using 4 NVIDIA H100 GPUs to run the full version of Mochi 1. We suggest using Flash attention to optimize memory usage.
Pre-requisites:
Step 1:
python3.10 -m venv mochi1-env
source mochi1-env/bin/activate:
Step 2: Clone the Genmo Github models
git clone https://github.com/genmoai/models
cd models
Step 3: Install dependencies:
pip install setuptools
pip install -r requirements.txt
sudo apt install ffmpeg
Step 4: Set up flash attention dependencies. This is optional and needed only if you are using
flash attention to optimize memory usage.
pip install packaging
pip install ninja
Step 5: Build with flash attention, which installs significantly faster when VRAM exceeds 96 GB.
pip install -e .[flash] --no-build-isolation
Step 6: Download weights from Genmo Mochi Hugging Face link, it might take several minutes as the files are quite large.
python3 ./scripts/download_weights.py /root/models
Step 7: Run the model via Gradio UI or directly from the terminal. If you run the Gradio demo, enable public share mode in the demo Python file, as shown in the screenshot below.
python3 ./demos/gradio_ui.py --model_dir /root/models
or
python3 ./demos/cli.py --model_dir /root/models --num_steps 200
In CLI mode, you can change the text prompt, number of frames, and model iterations either as arguments or in cli.py.
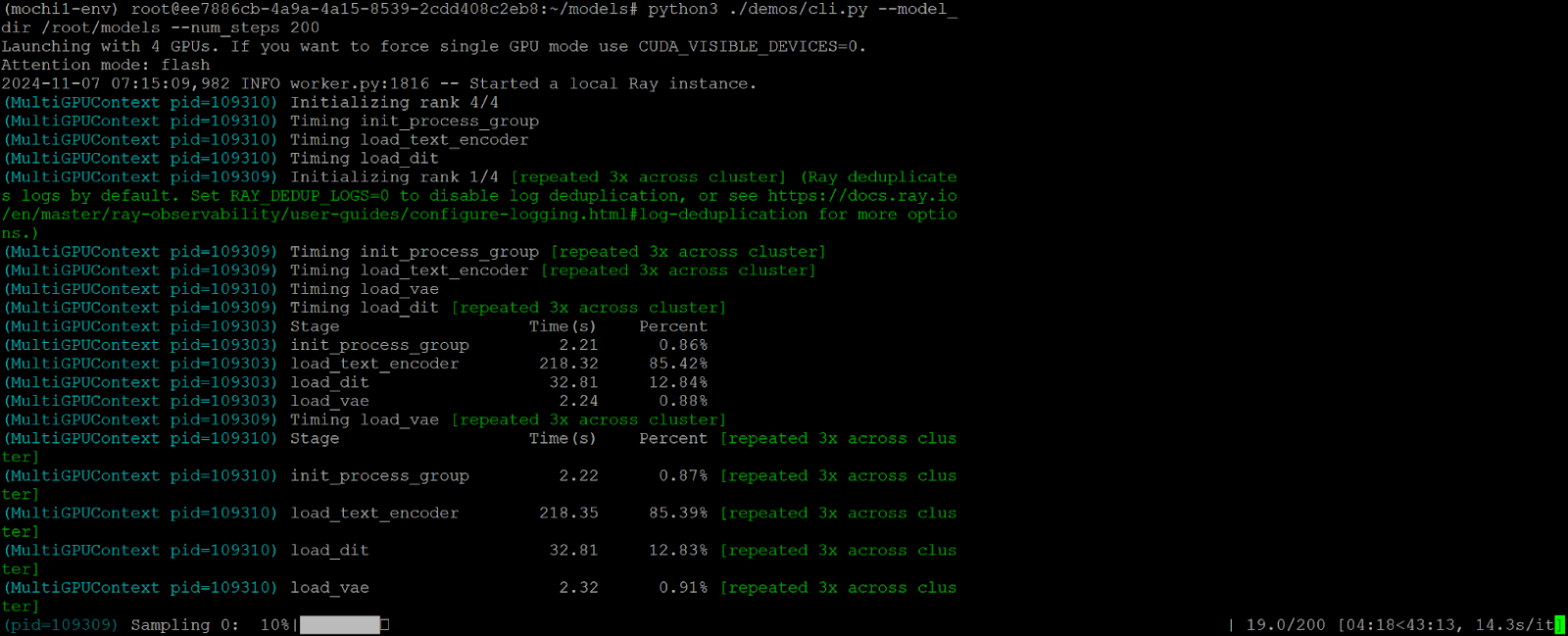
The screenshot below shows sampling in progress and the average iteration time at the bottom right side of the terminal.
Step 8: Create a Jupyter server from another terminal window and download the video file in a browser window.
pip install notebook
jupyter notebook --port 8889 --allow-root --no-browser --ip=0.0.0.0.
If you chose Gradio, you should see a link in the terminal after you run the demo file.

Imagine another AI reality. Build it on Ori.
Ori Global Cloud is the first AI infrastructure provider with the native expertise, comprehensive capabilities and end-to-endless flexibility to support any model, team, or scale. Here’s what you can do on Ori:





