The Llama 3.1 405B has been Meta’s flagship model with strong performance across contextual reasoning, complex problem-solving, and text generation. However, Meta’s latest model Llama 3.3 now provides nearly the same performance with a smaller model footprint, making open-source LLMs even more capable and affordable.
Llama 3.3 provides multilingual inputs and output with 7 languages in addition to English: French, German, Hindi, Italian, Portuguese, Spanish, and Thai. It also supports tool use for integrating with real-time data and to trigger 3rd party applications, making it suitable for a variety of use cases.
Here’s a quick rundown of Llama 3.3 70B specifications:
| |
Llama 3.3 |
|
Architecture
|
Optimized transformer architecture, tuned using supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF)
|
|
Parameters
|
70 billion |
|
Sequence length
|
128k tokens
|
|
Licensing
|
|
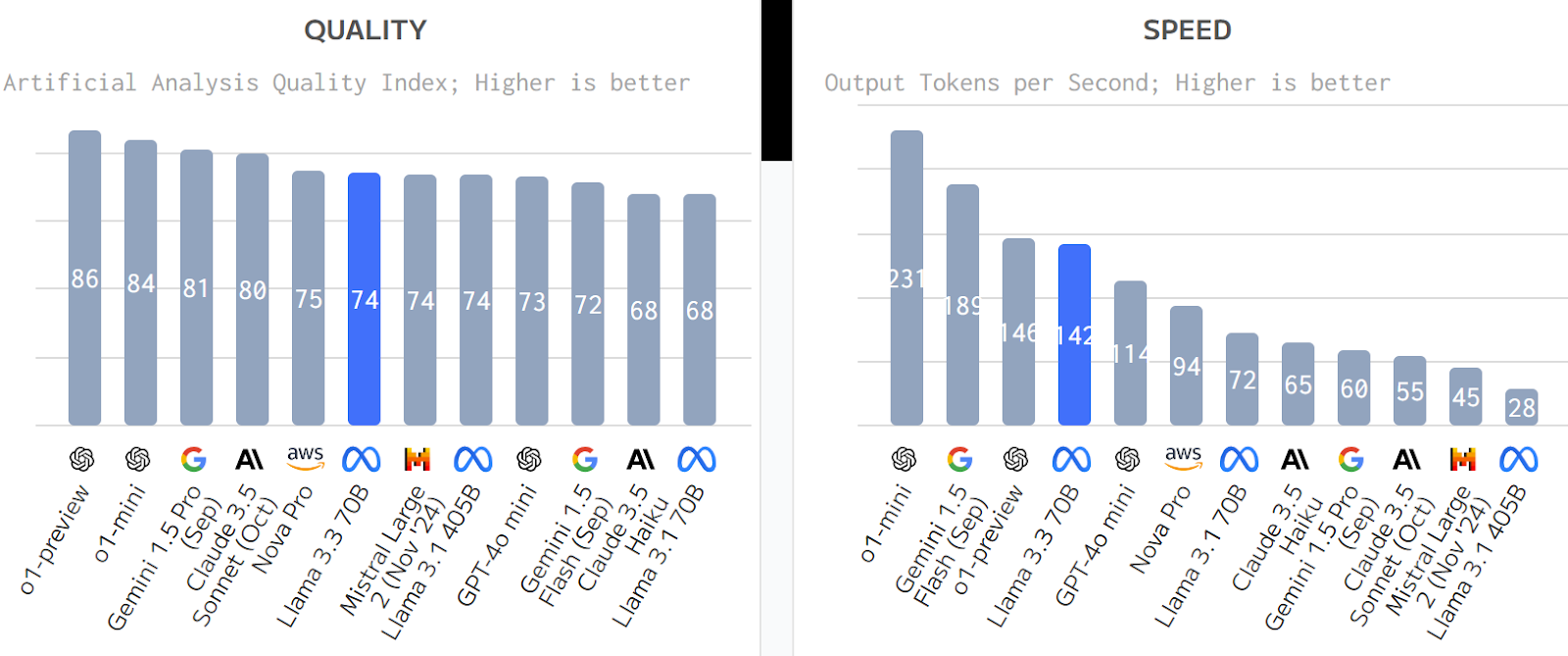
Performance benchmarks from Artificial Analysis indicate that Meta Llama 3.3 70B is the best-performing open source model currently available, and also being ahead of several closed source LLMs too.
How to use Llama 3.3 with Ollama and Open WebUI on an Ori virtual machine
Pre-requisites
apt install python3.11-venv
python3.11 -m venv llama-env
Activate the virtual environment
source llama-env/bin/activate
curl -fsSL https://ollama.com/install.sh | sh
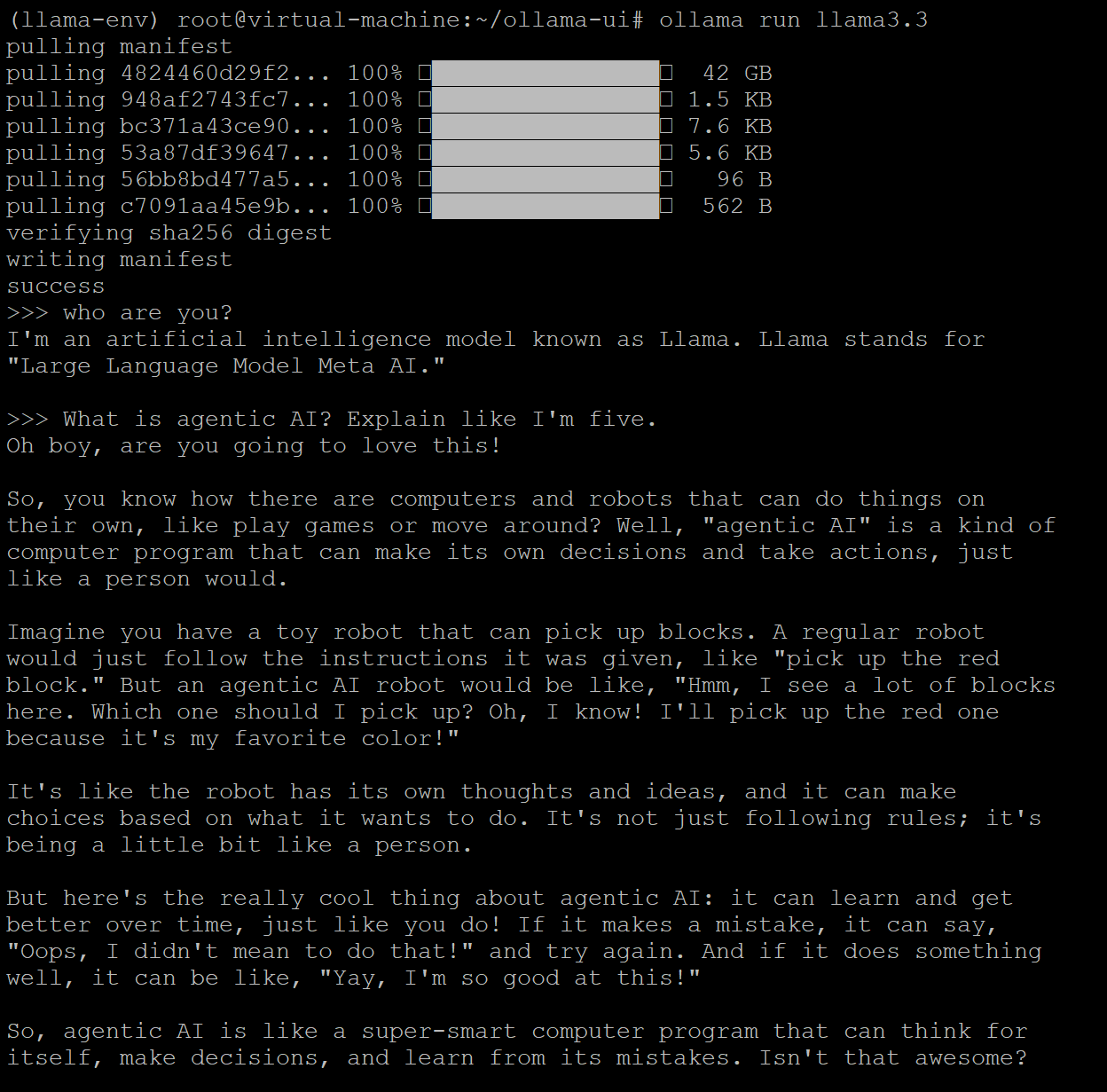
Step 3: Run Llama 3.3 with Ollama
ollama run llama3.3
Step 4: You can send messages directly through the terminal
Step 5: Install OpenWebui in another terminal window and run Llama 3.3 with Open WebUI
pip install open-webui
open-webui serve
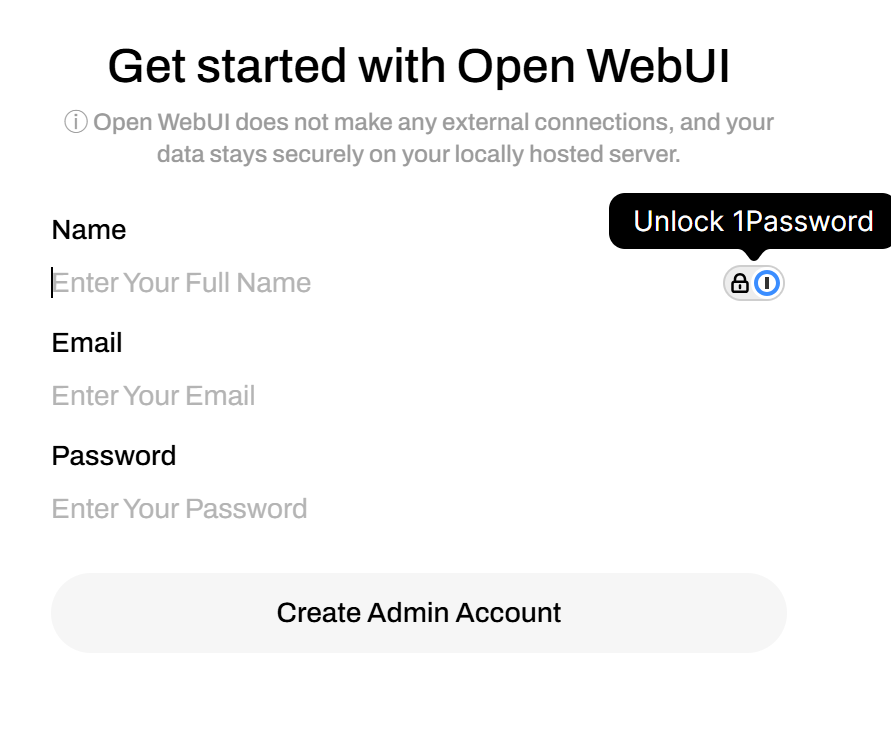
Click on “Get Started” to create an Open WebUI account, if you haven’t installed it on the virtual machine before.
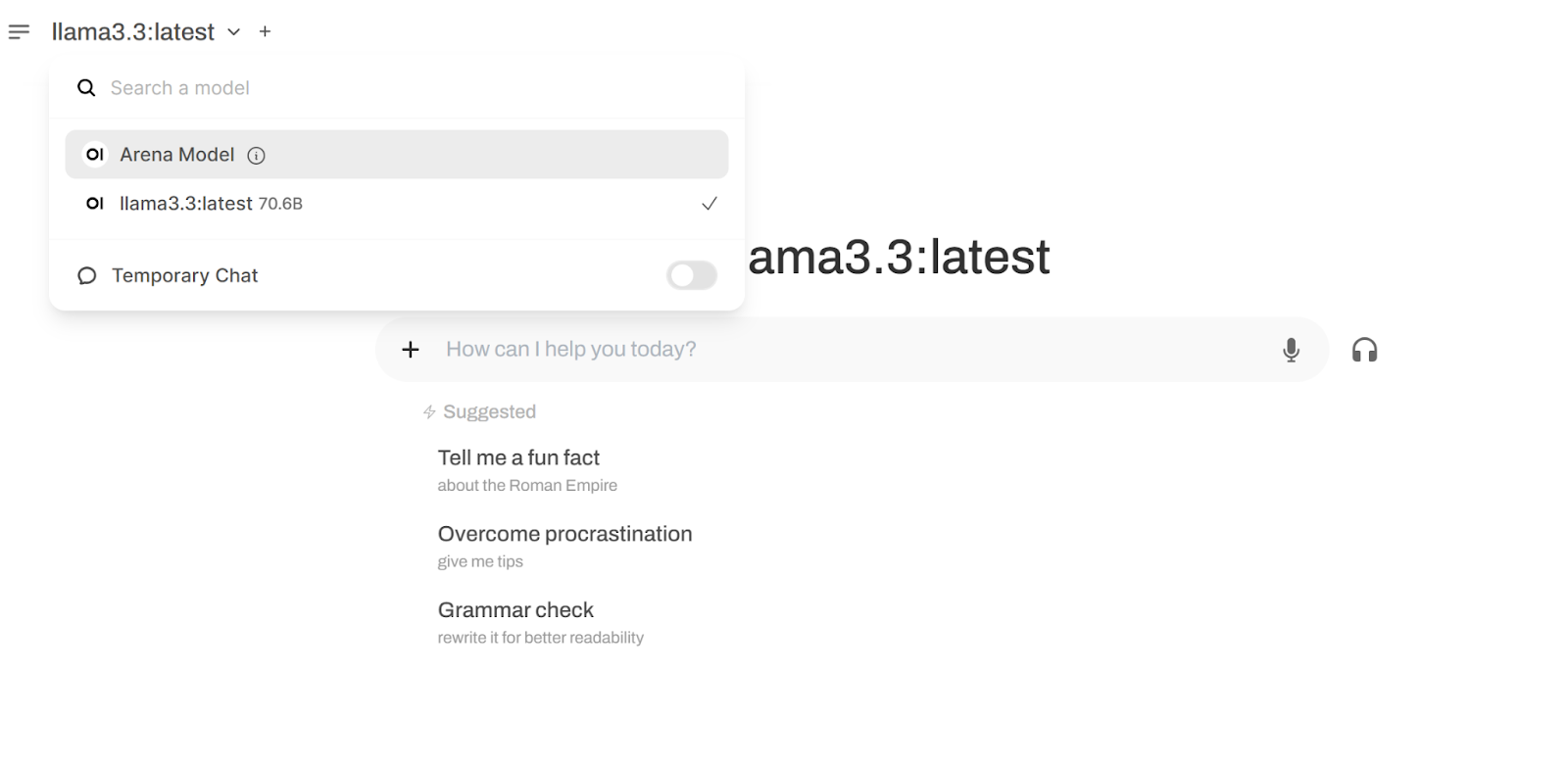
Step 6: Choose Llama 3.3 from the Models drop down and chat away!
Chart your own AI reality with Ori
Ori Global Cloud provides flexible infrastructure for any team, model, and scale. Backed by top-tier GPUs, performant storage, and AI-ready networking, Ori enables growing AI businesses and enterprises to deploy their AI models and applications in a variety of ways:
-
- GPU instances, on-demand virtual machines backed by top-tier GPUs to run AI workloads.
- Serverless Kubernetes helps you run inference at scale without having to manage infrastructure.
- Private Cloud delivers flexible, large-scale GPU clusters tailored to power ambitious AI projects.

.png?width=800&height=160&name=Discord%20Banner%20(2).png)