NVIDIA unveiled its latest GPU platform Blackwell at GTC earlier this year. This new platform, named after the pioneering mathematician and statistician David Blackwell, includes two powerful GPUs - the B100 and B200, as well as the GB200 supercomputer series. In this blog post, we explore what makes Blackwell GPUs unique and how they can unleash the next wave of AI computing.
What’s new in NVIDIA’s next generation of GPUs
AI Superchip: Each Blackwell superchip consists of two dies connected by 10TB/s C2C (chip-to-chip) interconnect, coming together as a single GPU with full
cache coherence. These dies built with TSMC’s custom 4NP fabrication process feature a whopping 208 billion transistors compared to the 80 billion transistors in Hopper.
The new NVIDIA Blackwell chips offer larger memory capacity for bigger models and more than double the memory bandwidth. This is crucial because a
memory wall can prevent large AI models from taking full advantage of GPU processing power. Another key feature of Blackwell is its incredibly fast GPU-to-GPU connection, enabling multiple GPUs to work together as unified compute blocks. Here’s the NVIDIA B100 vs H100 feature comparison:
| |
HGX H100 8-GPU
|
HGX B100 8-GPU
|
|
Form factor
|
8x NVIDIA H100 SXM
|
8x NVIDIA B100 SXM
|
|
Aggregate Memory Capacity
|
Up to 640GB
|
Up to 1.5TB
|
|
Aggregate Memory Bandwidth
|
27TB/s
|
64TB/s
|
|
Aggregate GPU-GPU Bandwidth
|
7.2TB/s
|
14.4TB/s
|
|
NVLink
|
4th Gen
|
5th Gen
|
|
NVSwitch
|
3rd Gen
|
4th Gen
|
2nd Gen Transformer Engine: features 5th Gen Tensor cores that support new quantization formats and precisions. This engine will greatly speed up the inference of Mixture of Experts (MoE) models by using dynamic range management and advanced microscaling formats. The dynamic range allows the engine to adjust and refine numerical formats to lower precision, continuously optimizing the models for better performance.
| |
HGX H100 8-GPU |
HGX B100 8-GPU |
| Tensor Core precisions |
FP64, TF32, BF16, FP16, FP8, INT8 |
FP64, TF32, BF16, FP16, FP8, INT8, FP6, FP4 |
| CUDA® Core precisions |
FP64, FP32, FP16, BF16, INT8 |
FP64, FP32, FP16, BF16 |
.png?width=800&height=160&name=5%20(1).png) Source: NVIDIA - Blackwell HGX performance data
Source: NVIDIA - Blackwell HGX performance dataMoE models are significantly faster when it comes to running inference when compared to equivalent non-expert models due to the efficiency of conditional computing and sparsity from expert parallelism.
However, these models require more VRAM because the system must load all experts and their parameters into memory. In addition to the substantially higher memory capacity and bandwidth, Blackwell’s lower precision formats and micro scaling help alleviate this problem by enabling larger models with more parameters to fit into GPUs.
Source: NVIDIA - Blackwell HGX performance data
This paper on Microscaling (MX) formats for generative AI discusses benchmark findings, showcasing the impressive potential of smaller precision formats for both training and inference, with only minor accuracy losses. As smaller precision formats advance, more ML developers are likely to embrace these innovations for model development.
 Source: NVIDIA - Blackwell HGX performance data
Source: NVIDIA - Blackwell HGX performance dataThe new Transformer Engine speeds up LLM training by enhancing the Nemo Framework and integrating expert parallelism techniques from Megatron-Core. We expect these advancements to pave the way for creating the first 10 trillion parameter model.
5th Generation NVLink: At 1.8TB/s bidirectional throughput per GPU, this new generation of GPU to GPU interconnect is
twice as fast as the previous gen and can enable seamless high-speed communication among up to 576 GPUs. Accelerated in-network computation makes NCCL
collective operations more efficient and helps GPUs reach synchronization faster. The latest generation of NVLink NVSwitch enables multi-GPU clusters such as the GB200 NVL72 for an accumulative bandwidth of 130TB/s for large models.
Confidential computing enhancements: The latest Blackwell GPUs now feature
Trusted Execution Environment (TEE) technology. While CPUs have supported TEE for a long time to ensure data confidentiality and integrity in applications like content authentication and secure financial transactions, NVIDIA GPUs now also offer TEE-I/O capabilities. This means enhanced data protection through inline protection on NVLink connections. Additionally, Blackwell GPUs provide data encryption at rest, in motion, and during computation.
Superfast decompression for data analytics: Blackwell can decompress data at a blistering 800GB/s speed with formats such as LZ4, Snappy and Deflate. The GB200 GPU charged by 8TB/s bandwidth of HBM3e (High Bandwidth Memory) and the lightning-fast NVLink-C2C interconnect of the Grace CPU makes the data pipeline extremely fast. NVIDIA’s benchmarks run on a GB200 GPU cluster
reveal 18x faster queries/sec than a traditional CPU and 6x faster than an H100 GPU, making GPUs more suitable for data analytics and database workflows.
Reliability, availability and serviceability (RAS) engine: performs automatic, built-in tests on computational cores and memory in the Blackwell chip. This is especially important for large supercomputer clusters, as it allows teams to replace underperforming GPU boards and keep performance high while protecting their GPU investments.
Understanding the Blackwell GPU lineup: B100 vs B200 vs GB200
The NVIDIA Blackwell family of GPU-based systems comprises HGX B100, HGX B200, DGX B200, and NVIDIA DGX supercomputers such as GB200 NVL36, and GB200 NVL72. The table below lists their specs and performance benchmarks provided by NVIDIA:
| |
HGX B100
|
HGX B200
|
GB200 NVL72
|
|
Form factor
|
8x NVIDIA B100 SXM
|
8x NVIDIA B200 SXM
|
1:2 GB Board (36 Grace CPU:72 Blackwell GPUs)
|
|
CPU Platform
|
x86
|
x86
|
Grace powered by 2,592 Arm® Neoverse V2 cores
|
|
Aggregate Memory
|
Up to 1.5TB
|
Up to 1.5TB
|
Up to 13.5 TB
|
|
Aggregate GPU - GPU Bandwidth
|
14.4 TB/s
|
14.4 TB/s
|
130 TB/s
|
|
FP4 Tensor Core
|
112 PFLOPS
|
144 PFLOPS
|
1,440 PFLOPS
|
|
FP8/FP6 Tensor Core
|
56 PFLOPS
|
72 PFLOPS
|
720 PFLOPS
|
|
INT8 Tensor Core
|
56 POPS
|
72 POPS
|
720 POPS
|
|
FP16/BF16 Tensor Core
|
28 PFLOPS
|
36 PFLOPS
|
360 PFLOPS
|
|
TF32 Tensor Core
|
14 PFLOPS
|
18 PFLOPS
|
180 PFLOPS
|
|
FP32
|
480 TFLOPS
|
640 TFLOPS
|
6,480 TFLOPS
|
|
FP64
|
240 TFLOPS
|
320 TFLOPS
|
3,240 TFLOPS
|
|
FP64 Tensor Core
|
240 TFLOPS
|
320 TFLOPS
|
3,240 TFLOPS
|
Scale models to multi-trillion parameters with NVIDIA GB200 supercomputers
The
GB200 superchip forms the core of GB200 supercomputers, combining 1 Grace CPU and 2 Blackwell GPUs in a memory-coherent, unified memory space.
The GB200 system comes in different versions, such as the GB200 NVL36 and GB200 NVL72, depending on the number of GPUs. Each rack can hold 9 or 18 GB200 compute node trays, depending on the design. These racks include cold plates and connections for liquid cooling, PCIe Gen 6 for fast networking, and NVLink connectors for seamless NVLink cable integration.
- GB200 NVL36 is one rack of 9x dual-GB200 (4 GPUs, 2 CPUs) compute nodes and 9x NVSwitch trays
- GB200 NVL72 can be two racks of 9x trays of dual-GB200 compute nodes and 9x NVSwitch trays
- GB200 NVL72 can also be one rack of 18x trays of dual-GB200 compute nodes and 9x NVSwitch trays
Here’s why GB200 supercomputers are perfect to handle the complexity of large models:
-
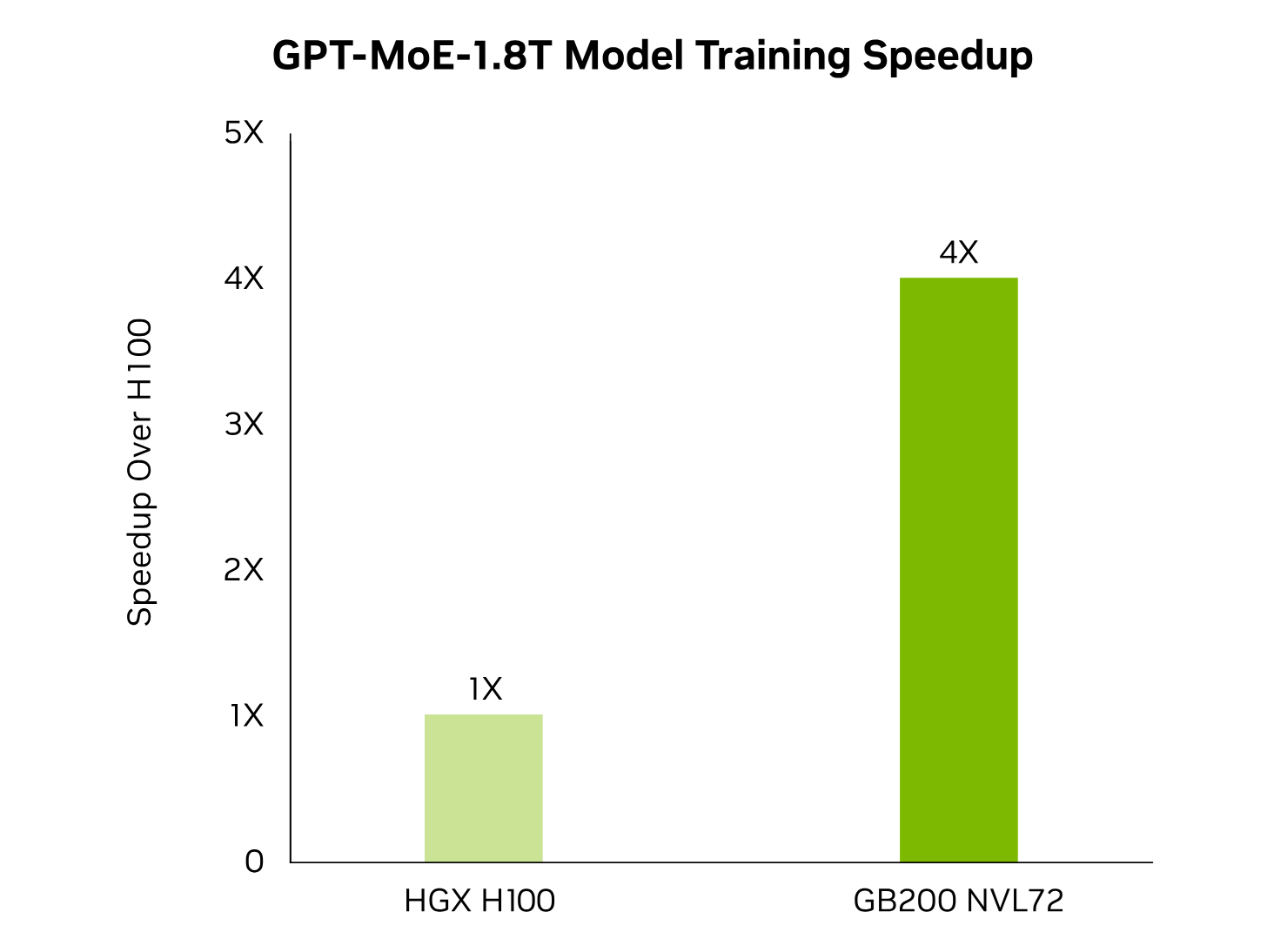
AI performance advantage from a massive compute block: The GB200 superchip is equipped with a new transformer engine, fifth-generation NVLink and 1.8 TB/s of GPU-to-GPU interconnect delivers 4X faster training performance for large language models like GPT-MoE-1.8T. The superchip also features InfiniBand networking and NVIDIA Magnum IO™ software ensures efficient scalability of extensive GPU computing clusters with up to 576 GPUs.
- Grace CPU with superior LPDDR5X memory: The Grace CPU is a powerhouse of 144 ARM v9 Neoverse cores delivering up to 7.1 TFLOPS of performance and can access 960GB of LPDDR5X RAM at 1TB/s memory bandwidth. This ultra-fast, low-power memory accelerates transactions while maintaining data integrity through error correction code (ECC), making it suitable for critical workloads.
- Blazing fast CPU interconnect with simplified NUMA: powered by 900GB/s NVLINK C2C interconnect which is several times faster than traditional PCIe interconnect.
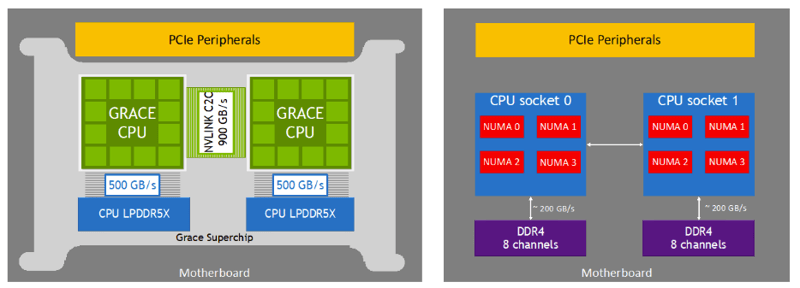
Source: NVIDIA - Grace CPU Whitepaper
.png?width=800&height=160&name=GB200%20(1).png)
Explore use cases for GB200 AI supercomputers
Here are some examples of use cases for supercomputers such as NVIDIA GBL200 NVL72:
- Unlocking training for trillion parameter models: With state-of-the-art (SOTA) models increasingly featuring more than trillion parameters, training a 1.8 trillion parameter is 4 times faster than an equivalent H100 GPU cluster.
- Scalable inference for powerful generative AI models: A Menlo Ventures study of business leaders on adopting generative AI revealed that 96% of computing spend on generative AI goes towards inference, highlighting the importance of optimizing performance for better ROI. The two main factors to consider when implementing inference are size and speed - businesses aim to offer instant experiences to their users as they transform their products and services with AI, regardless of the size of their customer base.
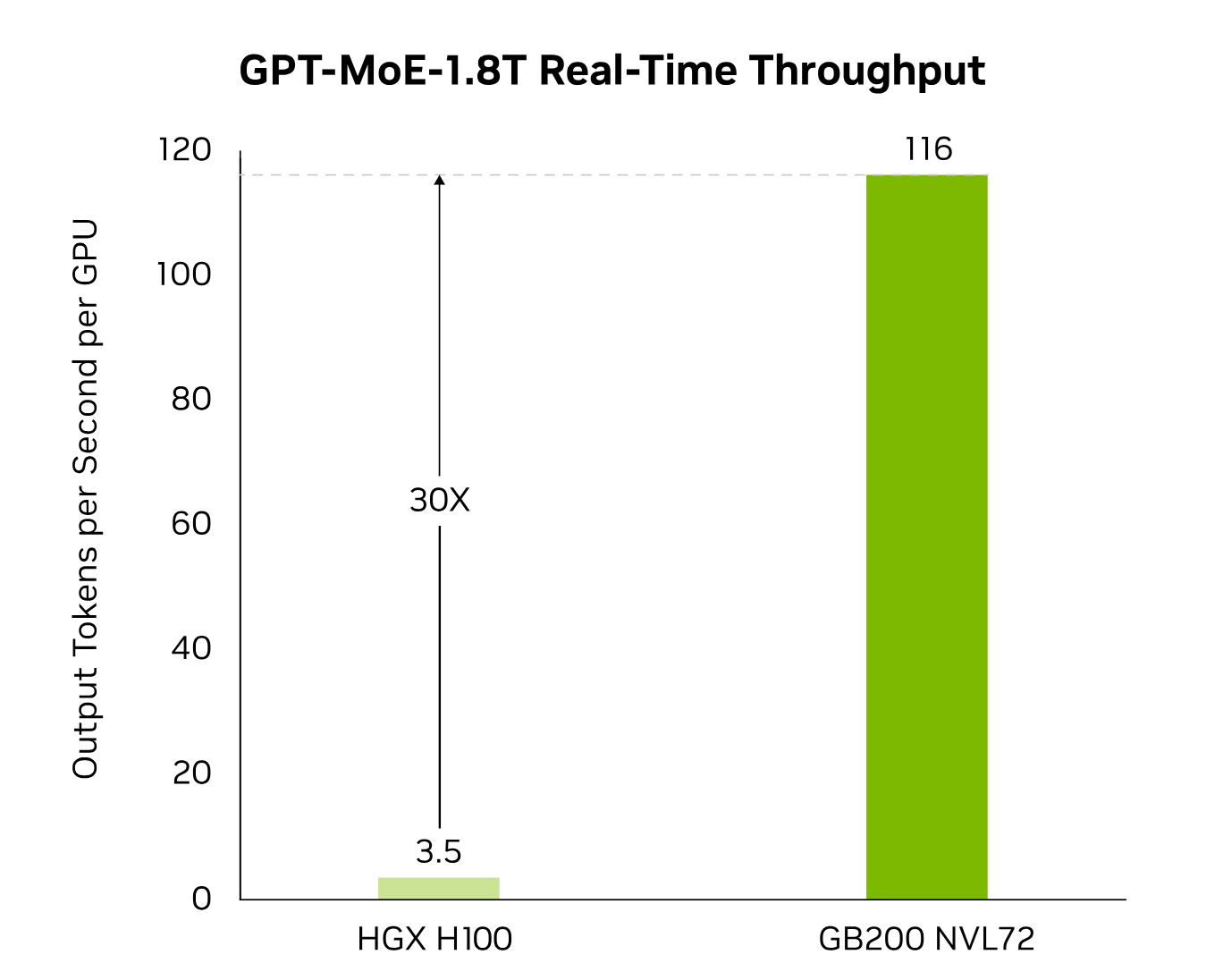
This is where the GB200 NVL72 cluster becomes crucial, providing up to 30 times better inference performance at real-time speeds bringing the scalability benefits of Blackwell's architecture to practical inference use cases in business and consumer applications.
- Seamless execution of Mixture of Experts (MoE) models: The massive aggregate memory of up to 13.5 TB in GB200 systems and incredibly fast GPU interconnect helps AI teams realize the potential of MoE models better than ever before. The visualization below shows how experts in an MoE model communicate with each other and across the model's layers. Without Blackwell’s NVLINK interconnect, NVIDIA estimates that GPUs would spend half their time on communication instead of computation.
- Superlative vector database and retrieval-augmented generation (RAG) performance: Grace CPU’s 960GB of memory and 900GB/s C2C link is perfect to accelerate RAG pipelines via low-latency vector search.
- Sustainable AI computing: Combined with energy savings from liquid cooling and the efficiency of the GB200 supercomputing system, GB200NVL72 is 25x more energy efficient when compared to an equivalent NVIDIA H100 cluster.
Power your AI with Blackwell GPUs on Ori
Want to leverage the power of NVIDIA Blackwell GPUs for your AI-focused business? Ori’s AI Native cloud is purpose-built for AI/ML workloads featuring top-notch GPUs, performant storage and AI-ready networking so you can:
Train and serve world-changing AI models on Ori! Reserve your Blackwell GPUs today!


-1.png?width=800&height=160&name=B100%20%26%20B200%20(3)-1.png)

