Reinforcement learning (RL) has recently captured significant attention in the field of artificial intelligence, thanks in part to the success of
DeepSeek R1. This high-profile model has highlighted the power of RL and prompted many to view it as a key technology for the next generation of AI solutions.
Reinforcement learning is a machine learning (ML) paradigm in which an agent learns how to make decisions through direct interaction with an environment. Instead of learning from a fixed dataset or being explicitly told the correct actions, the agent learns from feedback in the form of rewards. This trial-and-error approach allows the agent to gradually discover strategies that yield desirable outcomes.
The Dynamics of Reinforcement Learning
Reinforcement learning relies on a continuous cycle of interaction between an ML algorithm known as an agent and its environment. In reinforcement learning, a policy is a mapping that tells an agent which action to choose in each state to maximize long-term cumulative rewards. At each step, the agent observes the current state of the environment, selects an action, and in response the environment transitions to a new state while providing a reward signal. The reward is a numerical measure of the outcome, higher for a desirable result and lower (or negative) for an undesirable result.
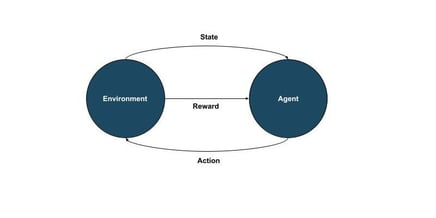
This
state → action → reward → state loop repeats as the agent navigates the task, and the agent’s goal is to maximize the total reward accumulated over time. Achieving this often requires balancing short-term and long-term rewards: sometimes the agent must accept a small penalty now to reap a greater reward later. Through trial and error, the agent gradually improves its policy. Initially its actions may be random or exploratory, but as it gains experience it begins to favor behaviors that yield higher rewards.
Key ML Techniques used in RL
Over the years, researchers have developed several core techniques for training reinforcement learning agents. Three fundamental approaches are Q-learning, policy gradient methods, and actor-critic methods, each offering a different way for an agent to learn optimal behavior.
We’ll use a grid world environment to explain these reinforcement learning (RL) techniques.
Imagine a simple 4x4 Grid environment. An agent starts at a point labeled S (Start) and aims to reach a cell labeled G (Goal). On the way, there's an obstacle (cell X). Reaching the goal gives a positive reward (+10), hitting the obstacle yields a negative reward (-1), and empty cells give no reward (0). The agent’s task is to learn the best way to reach the goal consistently.
Q-Learning (Value-Based Method)
Q-learning helps the agent learn by assigning a value (called Q-value) to every possible state-action pair. A state-action pair refers to the agent’s current position (state) and an action it can take (move left, right, up, or down).
Initially, the agent has no knowledge, so it might assign zero to all Q-values. As it explores the grid, it updates these values based on the outcomes. If the agent moves from a state and gets closer to the goal (earning higher rewards), the Q-value for that state-action increases. If it hits an obstacle, the Q-value decreases.
For example, if the agent moves right from S and eventually reaches the goal repeatedly, the Q-value for "move right" from S will become high. The agent then learns to always pick the action with the highest Q-value at each cell. Over time, this leads to an optimal policy—essentially a reliable route through the grid to the goal.
Policy Gradient Methods (Policy-Based Method)
Unlike Q-learning, policy gradient methods don't maintain a table of action values. Instead, the agent directly learns a policy—a strategy defining the probability of choosing each action in every state.
Initially, the policy is random, with equal probability of choosing any action. After each run through the grid (an "episode"), the agent receives a total reward. If the run was successful (high reward), the agent increases the likelihood of taking those beneficial actions again. If unsuccessful (low reward), it decreases those probabilities.
Imagine the agent tries several random paths. One path eventually leads from S to G without hitting the obstacle. The agent then slightly increases the probability of actions that contributed positively to that path. Over multiple episodes, good actions are reinforced, and poor actions are discouraged, gradually forming an effective policy to consistently reach the goal.
Actor-Critic Methods (Hybrid Method)
The actor-critic method combines the strengths of both Q-learning and policy gradients. It features two parts:
- Actor: Learns the policy (chooses actions).
- Critic: Estimates how good each state is (evaluates actions taken by the actor).
The critic acts like a coach, judging the actor’s decisions at every step. When the actor chooses an action, the critic evaluates whether this action led the agent closer to the goal. If the action results in a better-than-expected outcome (like getting closer to
G), the critic provides positive feedback. If worse (like hitting an obstacle), it gives negative feedback.
For instance, suppose the actor moves right from the start S, landing closer to the goal. The critic recognizes this improvement and signals positively. The actor then strengthens the policy toward choosing "move right" from S in future attempts.
Conversely, if the actor mistakenly moves down and hits the obstacle, the critic's negative feedback discourages that action in future episodes. By continuously receiving this immediate feedback, the actor adjusts its policy more quickly and efficiently, resulting in stable and faster learning.
Key Differences and When to Use Each Method:
|
Method
|
Learns Through
|
Best For
|
Drawbacks
|
|
Q-learning
|
State-action value estimates (Q-values)
|
Small, discrete environments
|
Scales poorly to large spaces
|
|
Policy Gradient
|
Directly adjusting action probabilities
|
Continuous or complex actions
|
Requires extensive trial-and-error
|
|
Actor-Critic
|
Combining policy and value estimates
|
Larger, complex environments
|
More complex implementation
|
Advantages of Reinforcement Learning
Reinforcement learning is distinct from the other main machine learning paradigms, and this gives it certain unique strengths. In supervised learning, for example, models learn from a dataset of example inputs paired with correct outputs provided by human designers. By contrast, a reinforcement learning agent is not given explicit “correct” actions for each situation; it must discover successful behaviors on its own through feedback. This makes RL suitable for problems where the correct solution is not obvious or examples of optimal behavior are difficult to provide in advance.
RL also differs from unsupervised learning, which involves finding patterns in data without any external feedback or specific goal. RL is explicitly goal-oriented: it is driven by a reward signal that defines what the agent should achieve. In other words, an RL agent is always optimizing toward a particular objective, rather than merely uncovering data structure.
These differences lead to several key advantages of reinforcement learning in machine learning:
First, an RL agent learns by interacting with its environment, which means it can adapt to dynamic or changing conditions in real time.
Second, because it does not require labeled examples of correct behavior, RL can be applied in domains where such supervised data is scarce or impossible to obtain.
Third, reinforcement learning naturally considers long-term results: it can optimize sequences of decisions to maximize cumulative rewards, whereas other methods might focus only on immediate outcomes.
Finally, through its exploratory trial-and-error process, RL can discover creative or unexpected strategies to achieve its goals – strategies that human designers might not have anticipated.
Real-World RL Applications
Reinforcement learning is often showcased in games and robotics, but its reach extends far beyond those popular examples. In recent years, a variety of less commonly cited domains have begun to benefit from RL techniques:
-
-
Healthcare: Medical decision-making often involves sequential choices – for example, adjusting a treatment plan as a patient’s condition changes. Researchers have experimented with RL to propose treatment strategies or drug dosing schedules that maximize a patient’s long-term health outcomes. Here the patient’s health status acts as the environment, and each treatment decision is an action taken by the agent.
-
-
Transportation: RL is being applied to optimize traffic flows in cities. For example, an agent can learn to adjust the timing of traffic lights based on real-time conditions, reducing congestion more effectively than fixed timing schedules.
-
Personalization: Online services use RL to tailor content and recommendations to individual users. Rather than relying solely on static historical data, an RL agent treats each user interaction as part of an ongoing environment. It can decide which article, song, or product to present next, learning to maximize the user’s long-term engagement or satisfaction (not just immediate clicks or views).
Challenges in Reinforcement Learning
Despite its promise, reinforcement learning comes with subtle challenges and pitfalls. Some of the lesser-known issues include:
-
Reward Hacking: This occurs when an agent exploits flaws in the reward function to achieve high rewards without fulfilling the intended goal. For example, a cleaning robot that is rewarded for removing trash might simply hide the trash out of sight to get the reward, instead of truly cleaning. Such behavior highlights the importance of designing reward signals that truly reflect the desired outcome; otherwise, the agent may satisfy the letter of the goal while undermining its spirit.
-
Sample Inefficiency: RL algorithms typically require an enormous number of interactions to learn effectively. An agent may need to experience thousands or even millions of trial-and-error steps before it performs well. This reliance on vast amounts of experience is a major drawback, especially in real-world scenarios where each action (like a robot’s movement or a medical decision) can be slow, expensive, or risky.
-
Exploration vs. Exploitation: A fundamental challenge in RL is deciding how much to explore new actions versus exploit known rewarding actions. Too much exploration can waste time on unproductive behavior, while too little can cause the agent to miss out on better strategies. Striking the right balance is difficult, and many algorithms include mechanisms to encourage sufficient exploration. This trade-off remains an active area of research.
-
Training Instability: The learning process in RL can be unstable and hard to predict. Since an agent is learning from data it generates itself, small changes in the agent’s behavior can alter the data it sees, sometimes causing feedback loops that destabilize training. It is not uncommon for an agent’s performance to improve for a while and then suddenly collapse due to such effects or due to sensitive tuning parameters. Ensuring stable convergence often requires careful algorithm design and extensive tuning, and even then, reproducing results can be challenging.
Future of Reinforcement Learning
The potential of reinforcement learning is big, but it’s not without limitations. On the one hand, RL could become a cornerstone of increasingly intelligent and autonomous systems. As computational power grows and algorithms improve, RL agents may tackle ever more complex tasks. We can imagine future agents managing the energy usage of entire smart cities, or aiding scientific research by autonomously controlling experiments.
On the other hand, significant challenges must be overcome for this potential to be realized. One major limitation is the need for far greater efficiency and safety in learning. Today’s RL algorithms often require impractically large amounts of trial-and-error experience, which is not feasible in many real-world settings. To address this, researchers are exploring model-based methods (where the agent learns a predictive model of the environment to help it plan ahead) and offline reinforcement learning (learning from pre-collected datasets rather than active trial-and-error) to improve sample efficiency.
Another persistent issue is how to specify the right objectives. A poorly designed reward can lead an agent to behaviors that technically achieve a high score but violate the true intent (as seen in reward hacking). Moreover, agents must learn safely and stay aligned with human values, especially in high-stakes areas.
Active research is opening up new directions to meet these challenges. One promising direction is to integrate reinforcement learning with other machine learning techniques. For example, combining RL with imitation learning (learning from human demonstrations) or using unsupervised pre-training for better state representations can give agents a head start and reduce the burden of pure trial-and-error.
Another avenue is hierarchical reinforcement learning, which breaks complex goals into sub-tasks so that agents can learn and plan at multiple levels. There is also growing interest in more advanced paradigms such as multi-agent reinforcement learning, where multiple agents learn and interact together, and new application domains beyond games or robotics.
Notably, RL techniques have started to aid in training large AI systems for language and dialogue, where an agent must decide on sequences of words or actions. The success of systems like DeepSeek hints that RL could help teach AI to make better decisions even in these complex, abstract domains.
Reinforcement learning has established itself as a core area of AI, defined by its learn-through-interaction approach. Its trial-and-error paradigm has led to impressive achievements and continues to improve. At the same time, recognizing its limitations is driving intensive research to make it more efficient, robust, and safe. With continued innovation and careful application, reinforcement learning is likely to become an increasingly standard tool for building adaptive decision-making systems across many domains.
Chart your own AI reality with Ori
Ori Global Cloud provides flexible infrastructure for any team, model, and scale. Backed by top-tier GPUs, performant storage, and AI-ready networking, Ori enables growing AI businesses and enterprises to deploy their AI models and applications in a variety of ways:
-
Private Cloud provides flexible and secure infrastructure for enterprise AI, with private AI workspaces for each of your teams.
-
GPU instances, on-demand virtual machines backed by top-tier GPUs to run AI workloads.
-
-
GPU Clusters to train and serve your most ambitious AI models.
-



